Research
Our primary interest lies in understanding how genes are regulated and, more specifically, finding out new modes of gene regulatory mechanisms and developing methods to inspect how the molecules are wired to each other. In the meantime, we are focusing on post-transcriptional regulations by the RNA binding proteins using high-throughput biochemistry and high-throughput nucleic acid sequencing. The transcriptome- and proteome-wide views by the high-throughput methods allow us to step closer to the rules of nature with less bias towards our current knowledge.
Revealing the uncharted 3′ extremity of mRNA
A 3′ end of an RNA is not such a place where boring repeats of adenosines hang out sluggishly. Poly(A) tails are rapidly tailored to express their payloads as instructed by the regulatory network. Moreover, reaching the cytoplasm, they are trimmed and elongated, uridylated and deuridylated, and even guanylated and deguanylated. Those marks altogether control the expression for precise quantity, timing, and life span of messages.
Much about poly(A) is still unclear due to the difficulties by their low complexity and dynamic nature. Our technique called TAIL-seq is currently the most widely used one for profiling the poly(A) tails across the thousands of different messenger RNAs. It has been applied to several exciting discoveries of unknown regulations to poly(A) tails: poly(A) uridylation (Lim, Zuber), G/A mixed-tailing (Lim), initiation of selective RNA degradation in the vertebrate reproduction (Chang, Morgan), restriction of LINE-1 transcripts (Warkocki), defensive responses to viral RNAs (Le Pen, Batra).
Despite the advances by the approach, there are still several important biological questions that cannot be easily answered using TAIL-seq.
-
TAIL-seq can’t distinguish isoforms. TAIL-seq reads lack the exact information about the transcript. It is difficult to tell which one is related to a read among the alternatively spliced (or alternatively polyadenylated) isoforms. Knowing the sequence composition of 3′ UTR associated with each poly(A) tail is crucial to understand regulatory elements in the controls of RNA stability and translation.
-
Long poly(A) tails are often underestimated in TAIL-seq. Multiple steps bring a bias against long poly(A) tails in TAIL-seq. PCR amplification and interference to sequencing reactions are the most prominent sources that make long poly(A) tails stand less in the result. To clarify what’s happening to the long poly(A) tails in the cell, we need a reliable way to observe the tails more accurately in a high-throughput fashion.
-
TAIL-seq is limited to highly expressed transcripts. Enough tags are essential for high-resolution measurement of poly(A) length profiling of a gene. Lowly expressed genes or transcripts often fail to yield enough poly(A) tags in the result, while many of them are pivotal regulators that change the fate of the cell. We’re working on improving the library preparation and sequencing to make it easier, efficient, yet more sensitive.
Single-molecule RNA analysis in a sub-nucleotide resolution
The same genome gives birth to RNAs, but every RNA lives a different life. Polyadenylation, splicing, base modifications, capping, folding, subcellular localization, and coverings with thousands of RNA-binding proteins make every molecule unique. To fully understand the complex regulations between the genomic DNA and protein outputs, we need an ability to read the information inside the single RNA molecules one by one. Nanopore direct sequencing is an enabling technology to reveal the missing connections in the genetic circuitry.
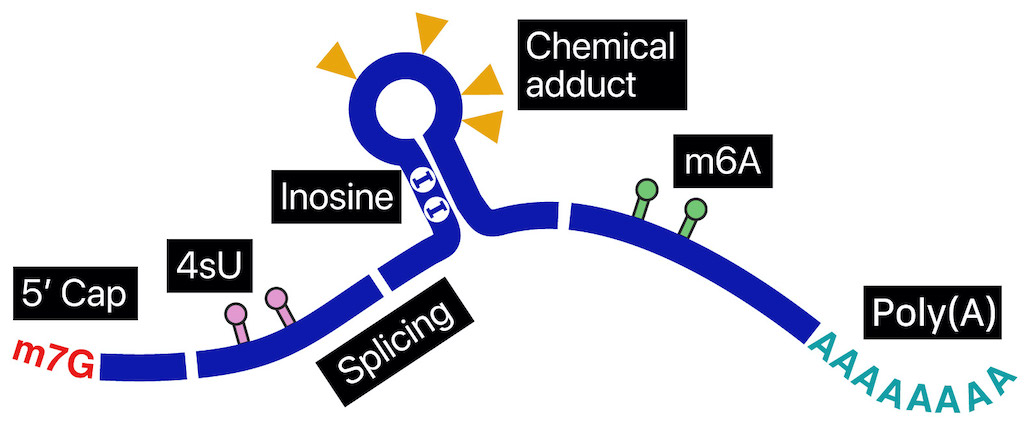
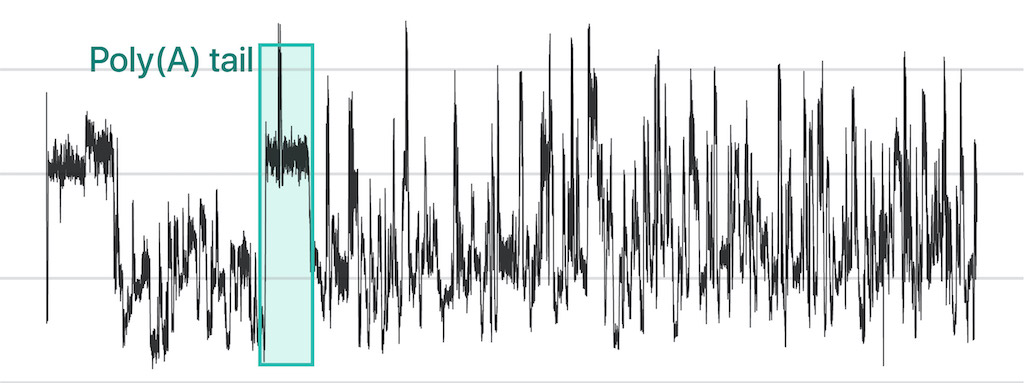
In nanopore direct RNA sequencing (DRS), a nucleic acid migrates through “nanopore,” a tiny hole, embedded within a bilayer membrane. The ionic current is distrubed in uniquely different levels depending on the RNA base passing through the hole. This information presents special opportunities to survey sub-nucleotide-level details throughout a full-length RNA molecule.
We are developing a full suite comprising of biochemical methods as well as machine learning applications to adopt direct RNA sequencing to RNA biology. With those tools, we will further scrutinize the unclear parts of RNA regulatory mechanisms.